
The integrated ACGT environment
The ACGT platform aims to facilitate the seamless and secure access and analysis of multi-level clinico-genomic data using high-performing knowledge discovery operations and services. In order to achieve this goal, a well defined data analysis and processing environment needs to be in place, which would make possible the integration and interoperability of the different ACGT components. The goal of the integration process is to make disparate and heterogeneous applications work together so as to produce a unified set of functionality, possibly by complementing each other. Whereas integration is concerned with the building of a unified system that incorporates the functionality of its constituent parts, interoperability is more a virtue of a single software entity so that it can be easily deployed in an unanticipated environment. Therefore defining interoperability guidelines is a prerequisite for building the ACGT integrated environment.

In ACGT two notions of interoperability have been specified: the syntactic and semantic interoperability. Syntactic interoperability of software may be defined as the ability for multiple software components to interact regardless of their implementation programming language or hardware platform. Syntactic interoperability in ACGT requires standardization of data formats and data structures for the representation of, access to and exchange between biomedical informatics resources. On the other hand, semantic interoperability is related to the "meaning" of the exchanged information and it is the ability of two or more interacting computer systems to have the meaning of that information accurately and automatically interpreted and "understood". To achieve syntactic interoperability programming and messaging interfaces must conform to standards that specify consistent syntax and format across all systems in the ACGT environment. Furthermore, in order to support the semantic interoperability, all data must be annotated with metadata by means of terminology and ontology identifiers and codes that support aggregation, comparison, summarization, mining, etc. of information that resides in separate resources.
The complexity and the diversity of user requirements have a strong impact on the design of the ACGT architecture. The adopted architecture for ACGT is shown in Figure 1. A layered approach has been followed for providing different levels of abstraction and a classification of functionality into groups of homologous software entities. In this approach we consider the security services and components to be pervasive throughout ACGT so as to provide both for the user management, access rights management and enforcement, and trust bindings that are facilitated by the grid and domain specific security requirements like pseudonymization. Apart from the security requirements, the grid infrastructure and other services are located in the first (lowest) two layers: the Common Grid Layer and the Advanced Grid Middleware Layer. The upper layer is where the user access services, such as the portal and the visualization tools, reside. Finally, the Bioinformatics and Knowledge Discovery Services are the "workhorse" of ACGT and the corresponding layer is where the majority of ACGT specific services lie.
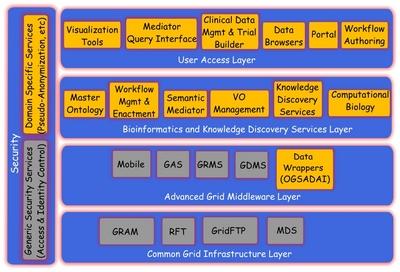
Figure 1. The ACGT Architecture
For the realization of this architecture a multidisciplinary and multi paradigm approach has been followed. The ACGT platform is designed according to the following technologies and standards: Service Oriented Architecture (Web Services), the Grid, and the Semantic Web. In particular, Grid and Web Services technologies are the basis for defining the syntactic interoperability:
- The machine to machine communication is performed via XML programmatic interfaces over web transport protocols (SOAP), which are specified using the Web Service Definition Language (WSDL). These common data representation and service specification formats, when properly deployed, make the syntactic integration of the ACGT components a lot easier.
- The Grid defines the general security framework, the virtual organization abstraction, the user management mechanisms, authorization definition and enforcement etc. It also provides the computational and data storage infrastructure that is required for the management and processing of large clinical and genomic data sets.
On the other hand, the Semantic Web provides the infrastructure for the semantic interoperability: it adds the knowledge representation mechanisms by the means of RDF Schemas and OWL ontologies, the unique identification of concepts and resources through the URIs, the implementation-neutral query facilities with the SPARQL "universal" query language and the associated query interfaces, etc. These enabling technologies are used for the specification of the service related metadata, such as the semantic description of input and output parameters, the service functionality and intent annotations, the quality of services, etc. These semantic annotations can be used in a multitude of ways: service discovery, selection, and "matchmaking" scenarios, quality control and monitoring, etc.
The interoperability of the ACGT components is tested by the developers but it's also continually exercised by the users themselves. The ACGT Workflow Editor is the end user application for the designing and execution of high level scientific workflows. In this web based application the users are facilitated to graphically combine the data retrieval and discovery services and the knowledge extraction and data analysis tools. The definition of the syntactic representation of the data and most importantly the annotation of the services with semantic metadata descriptions gives a lot of flexibility in the workflow editor for supporting user friendliness and intelligence. If properly annotated, incompatible services cannot be directly connected because the data types of their inputs and outputs do not conform to each other, either in the syntactic or the semantic level, while service recommendation and intelligent workflow composition can be also supported.
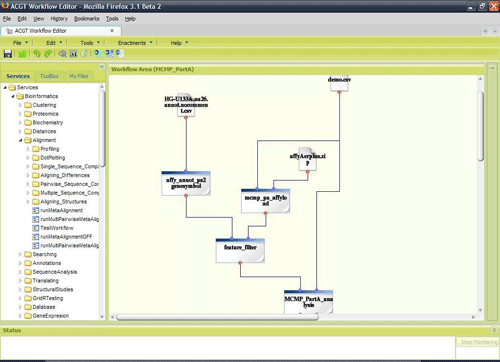
In conclusion the integrated ACGT environment is built through the adoption of common industry and open standards and well known software engineering practices. The semantic annotation of data and services is of utmost importance and in ACGT the necessary infrastructure (service and data type ontologies, service and metadata registries, etc.) has been designed and implemented. Finally, the definition of integration policies and interoperability guidelines is also important for connecting to and interacting with third party services and resources and making them available inside the ACGT platform.
Stelios Sfakianakis
Biomedical Informatics Laboratory
Institute of Computer Science
FORTH